


Read Time:
7
Minutes
Digital Transformation
March 17, 2025
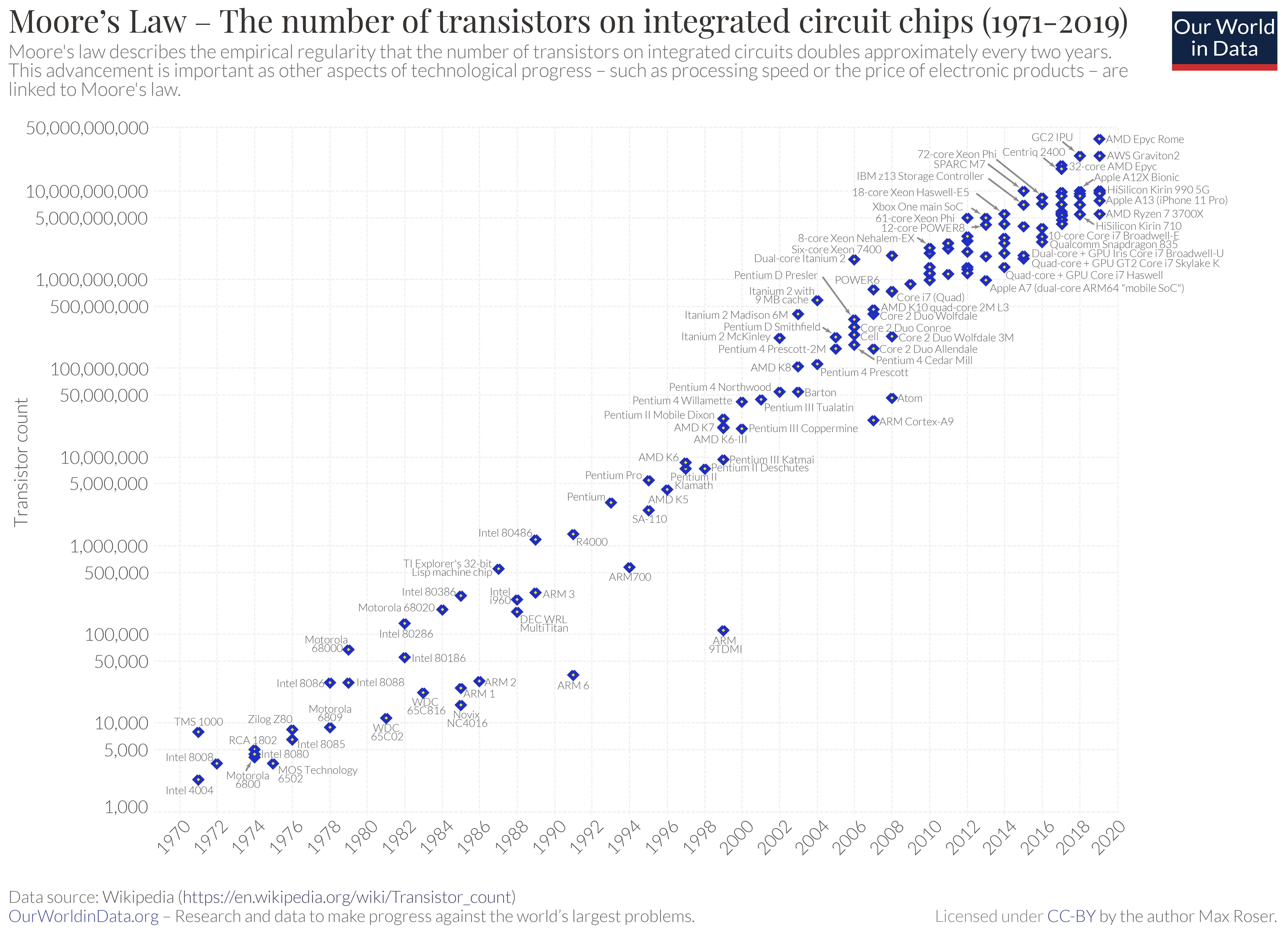
Tuning is the new Moore’s Law
Whichever way you look at it, the steady geometric growth in computing power we’ve all become accustomed to will not – cannot – go on forever.
In a seminal paper in 1965, Gordon Moore, CEO of Intel, observed a doubling of the number of transistors that could be fabricated into an integrated circuit every year. In 1975 he revised this to doubling the number of components every 2 years. Amazingly, this growth rate has persisted pretty much uninterrupted until now, enabling the life-changing technologies we all enjoy today. However, miniaturisation, cramming ever more transistors into silicon, has brought us close to some insurmountable limits that will stop Moore’s Law dead in its tracks.

Switching and memory elements (transistors) are now being etched onto silicon at scales almost as small as individual atoms, bringing us perilously close to the limits of conventional physics. Try to go any smaller and we leave the world of classical physics and end-up, not by choice, in a realm where quantum effects lead to chaos. Quantum mechanics says there’s a non-zero probability that electrons on one side of an insulator can be on the other side, at the same time, causing corruption of code and data. Binary digits are represented by electrons moving through transistors limited by the speed of light. A transistors capacity to store electrons, capacitance, goes down with miniaturisation and its resistance to current flow goes up, causing a deadly embrace that cannot easily be overcome. The limits of transistor packing density have most significant impact in supercomputer and datacentre infrastructures, prompting a rethink in processor and system architecture designs.
Rethink designs and change developer habits
Unlocking additional power for research programs to better understand climate change, develop new materials and improve drug design has increased demand for specialist AI acceleration chips tuned for the algebra of deep learning. Use of field-programmable gate arrays (FPGAs) to accelerate search, general-purpose graphic processing units (GPUs) to offload matrix and vector computations, have proven successful in massively parallel processing applications. Application-specific integrated circuits (ASICs) are popular with cryptocurrency miners. Tuning architectures that date back to the 1940s has provided some short-term gains but taking advantage of these changes requires software developers to rethink their designs and change their habits.

We must also be realistic about the timeline, not just for developing and proving new processing methods such as quantum computing, but also the inertia and resistance to replacing today’s pervasive IT infrastructure, operations and management processes. Therefore, until new technologies based on the spin of electrons (spintronics) instead of a charge, or computational substrates made of non-silicon materials such as carbon nanotubes or biological computers using cells and DNA as integrated circuits, or brain-machine hybrids and telepathic networking become operational realities, we should be doing as much as we can to sweat today’s IT assets.
It’s a big mistake to use Moore’s Law as a proxy for costs. One cannot assume that a doubling of performance is equivalent to halving the price. The implied correlation masks the fact that chip manufacture has become prohibitively expensive and the environmental costs of the power and cooling, needed to keep massive datacentres operational, may snuff-out the need for continual growth (if the power runs out and the lights go off).
A new decree
What we need, as an alternative to Moore’s Law, is a new decree pushing us to attempt to double what can be done with today’s IT infrastructure every 2 years. That may sound challenging but consider this:
- Why does it take a 4GHz CPU and 8GB memory to browse Facebook?
- We recently celebrated the 50th anniversary of our first steps on another world. Neil Armstrong and Edwin “Buzz” Aldrin successfully landed their Apollo Lunar Module, Eagle, a quarter of a million miles away in the Sea of Tranquillity on the Moon. The Eagle’s 2MHz guidance computer had 2048 x 16bit words of modifiable magnetic-core memory (random access memory, RAM) and 36,864 words of core rope memory (read-only memory – ROM). That’s the equivalent of just 76K bytes of storage and performance comparable to an Apple II home computer from the late 1970s.
Years of IT infrastructure performance growth and pressure to release software early has led to poorly optimised solutions that rely on seemingly endless compute resources. Whether tuning software and systems for faster execution times, tuning for reduced memory usage, or tuning configurations for more efficient use of hardware, here at Ntegra we focus on making systems do more with less, and we believe that “tuning is the new Moore’s Law.”
Our system performance tuning experts measure current throughput and performance, identify bottlenecks and opportunities to improve, modify systems and remove bottlenecks, and compare throughput and performance against pre-tuning baselines. It’s then a simple choice to adopt the tuning modifications if the performance has improved or roll-back to the way it was. We’ve applied this pragmatic approach many times and never had to roll-back and here are a few examples of this in context:
Avoid N-Squared Operations
One of our clients’ development teams had created PL/SQL stored procedures that did not scale with data volumes. Projections showed that each day’s data would take longer than a day to process, and there was little or no understanding of query performance optimisation, parallelisation and tuning methods within the team. Ntegra was engaged to analyse and identify high workload statements, verify execution plans and ensure they could be made to perform appropriately. We worked to identify procedural logic such as deeply nested loops and inefficient read/write combinations, implemented corrective actions and significantly reducing daily processing times to within just a few minutes. We also provided coaching to enable the SI team to spot and avoid O(n2) workloads that should only require O(n) operations. These cause exponential increases in processing time as data volumes grow in a linear fashion.
Odd and Unpredictable Behaviour
When developing, refactoring and migrating systems, non-functional thinking is essential for reducing the incidence of processing and storage bloat. Developers and testers should also be aware of the bigger picture, thinking about what their code and systems are running on and the circumstances that may cause them to behave in odd or unpredictable ways. In a recent project, a vendor was keen to demonstrate that a code fragment performed and scaled in a linear fashion when treating 100, 1,000, 10,000 and 100,000 rows of data. After we disabled auto-scaling in the cloud environment and re-ran the tests, things didn’t look so good!
Low Hanging Fruit
In another example, we worked with a team trying to improve a long-running process because their load testing and profiling had spotted it taking around 10 minutes to complete during the overnight batch. Looking more closely, we soon spotted the process was called just once as part of a procedure that also called another 1.5 second process around 10,000 times (just over 4 hours in total). By improving the “smaller” process’s runtime, we were able to reduce the total batch runtime by nearly 3 hours, proving that context really matters and it’s not always the lowest hanging fruit you should be tackling.
Advantage of Parallelisation
During the initial environment setup and pipe cleaning phase of an Innovation Lab we undertook for one of our Financial Services clients, it quickly became apparent that PL/SQL stored procedures were being used extensively in their processing solution. Use of nested cursors and loops caused serialisation of processes, forcing them to run on single threads and, therefore, limiting the advantage of the parallelisation that we were trying to demonstrate. To overcome this constraint, it was necessary to decompose stored procedure logic and recreate queries with the logic embedded in a ‘case’ statement within the ‘where’ clause of a single query. This resulted in the query running n-ways-parallel, demonstrating incredible performance improvements.
Learn More
If you’d like to learn more about how systems performance tuning can help your business or hear more about our experience, anecdotes and case studies in non-functional thinking, please get in touch.

{kind=link}